Politicians’ emails provide historians an exciting window into the fast-paced, formal and informal, and sometimes chaotic world of politics. The sheer number of emails, however, can prove challenging for historians, as archives routinely contain tens of thousands of messages with different recipients. Researchers need months or even years to study such a large number of records, but I give my students only 14 weeks to study over 30,000 emails. They are able to accomplish this feat by employing Voyant Tools.
My introductory course in digital history at the University of Luxembourg provides history MA students with an overview of various digital methods and tools. In the course, students confront a somewhat homogenous dataset that is too large for them to read yet diverse enough to explore and generate distinct results using different tools. I introduce students to several tools to explore the dataset and encourage them to ask general questions about what the dataset is about, when certain events in the dataset happen, where the mentioned locations are, and who the involved actors are.
The last two years, we have used the Hillary Clinton Email Archive from WikiLeaks as our dataset. Created through a Freedom of Information Act (FOIA) request, the archive encompasses over 30,000 emails sent by Hillary Clinton and her team at the US State Department primarily between 2010 and 2014. The emails are organized according to when they were released, from 1 to 33,727, rather than according to when they were sent. WikiLeaks offers an online interface, with one page per email that can be downloaded as an individual PDF. To analyze the emails as a collection rather than individually, however, instructors will need to scrape the archive to create a usable dataset.
Toward this end, my colleagues and I have written a script to scrape the entire Hillary Clinton Email Archive. The resulting spreadsheet contains metadata from all the emails, as well as individual text files for each email. Instructors looking to replicate the dataset can find instructions on how to install and use the scripts on our GitHub page. With email metadata such as sender, receiver(s), date, and subject line, as well as the content of each individual email, the archive offers plenty of material for students to test data-driven research methods.
Using Voyant
What can we find out about Hillary Clinton and her team’s main interests between 2010 and 2014? For the purpose of the course, students receive an open-ended assignment: upload the emails into Voyant Tools and try to find something of interest. Students are not graded on their specific finding, but on the process of getting to it.
Developed and maintained by the scholars Stéfan Sinclair (McGill Univ.) and Geoffrey Rockwell (Univ. of Alberta), Voyant Tools is a web-based application where scholars and students can directly add or upload texts in order to perform textual analysis. Once users have uploaded one or more texts, Voyant provides five views: a word cloud (called “cirrus”) of common terms in the dataset; a reader with the uploaded texts; a trends view that allows users to select one or several terms in the dataset to create a frequency chart; a summary view describing some characteristics of the dataset such as number of words per document; and finally, a contexts view where users can select terms in the dataset to see how they are used in different sentences. Voyant offers many additional tools; details can be found in its documentation.
One problem with Voyant is that it is not really designed to handle thousands of small text files. One solution is to combine a thousand emails into a single text file, which Voyant handles with relative ease. A downside to this approach is that many of the possible views in Voyant, including the trends or summary views, become less detailed. Another solution is to use a smaller subset of the entire collection, which also allows for comparisons. For the assignment described in this blogpost, students received two collections of emails numbered 6000 to 6999 and 7000 to 7999. The samples included emails from dates spanning the entire duration of the archive. Later, for the final assignment, students received all emails and specified a selection themselves based on period, person, or subject.
Results from Students
When students get such an open-ended assignment, the first tool they always use is the word cloud, hoping to find a word that catches their attention. If they do not find much of interest, they follow a process of filtering out words from the word cloud. Eventually, most students conclude that the word cloud does not show them much of interest.
The second view students like to play with is the trends view. This view requires them to enter keywords, so students have to investigate what was happening at the time to see how Clinton and her team discussed it. Last year, two students compared the use of “Egypt” and “Mubarak” in the two collections. They found that in the first sample collection, the two words strongly correlated, while in the second sample Mubarak remained flat throughout, indicating that he perhaps was no longer of interest to Hillary Clinton and her team.
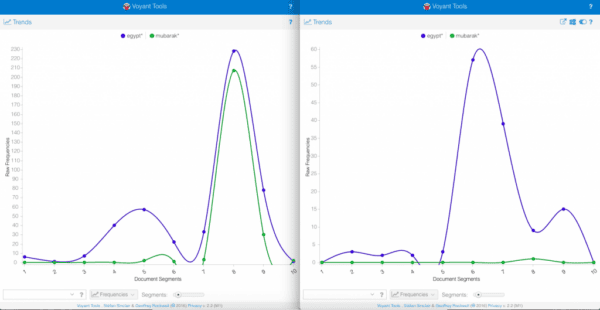
Trends view in Voyant
Another group of students chose to use the contexts view for a close-reading exercise with the goal of finding out how Hillary Clinton and her team talked about Syrian president Bashar al-Assad, and noticed that the language was very clearly opposed to his regime.
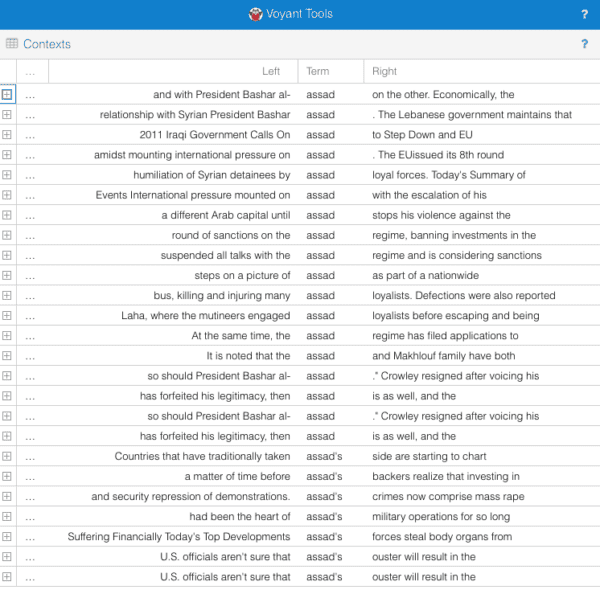
Contexts view in Voyant
A third group of students decided to use the links view to see which people copied each other on emails. They found that Cheryl Mills (the chief of staff to Hillary Clinton) was much more prominent in the second set of emails compared to the first, opening up new questions as to why staff members were included more often in emails during some periods than others.
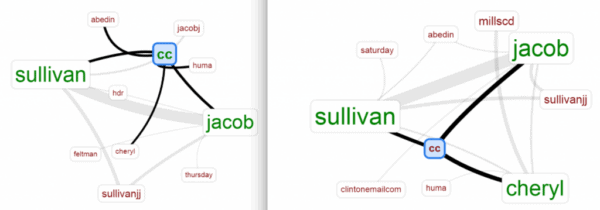
Links view in Voyant
Conclusion
This open-ended assignment has three main learning outcomes:
- Students soon learn that they need to move between distant reading and close reading to find and make sense of the results.
- Students learn that they have to consider the context of the dataset (why does Mubarak disappear from the discussion?) as well its provenance (why is Moscow mentioned surprisingly little?).
- Students learn that they need to continuously change and adapt their research question, the tools at hand, and the available dataset. Sometimes the dataset does not support their research question; sometimes their research question does not work with the tool.
It takes some willpower for students to move beyond the word cloud, and although the trends view is fairly intuitive, the other views require creativity and curiosity both in terms of asking questions that the tools can handle, and interpreting the outcomes. In my experience, however, once students take up the challenge, Voyant becomes the tool in my course they see themselves using the most in the future.
This post first appeared on AHA Today.
Max Kemman (www.maxkemman.nl, @MaxKemman) is a PhD candidate at the Luxembourg Centre for Contemporary & Digital History (C2DH) at the University of Luxembourg. His PhD research is an ethnographic study of how digital history is conducted through negotiations between historians and computational researchers.
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Attribution must provide author name, article title, Perspectives on History, date of publication, and a link to this page. This license applies only to the article, not to text or images used here by permission.


