In an age of information overload and technological advance, our research methods are rapidly changing. So too, therefore, are expectations. With the increasing ubiquity of digital archives has come the expectation that we must use them; with rapid advances in search technology has come the requirement that our research be more comprehensive than ever before. Yet, we today are a transitional generation of historians strung between physical and digital worlds. We work with a scruffy assortment of research formats: typed notes, PDFs and archive photographs alongside microfilm printouts, photocopies, and a scrawl of illegible notes from that one archive on your research trip that wouldn’t let you bring in your laptop. Consolidating this untidy sprawl has become a problem in itself, one to which scholars usually apply themselves only incidentally in the actual task of research.
DevonThink is a piece of research management software for Macintosh. It’s an incredibly smart, flexibly structured, fully searchable database, a one-stop container into which one can deposit all manner of research material. It’s extraordinarily permissive: DevonThink will take text files, Word documents, PDFs, JPGs, PNGs, web bookmarks, RSS feeds and more. DevonThink was designed to be a solution to the problem of managing the data we collect, and its ultimate solution is to ‘go paperless’: every scrap of your research can be transformed into bytes and deposited into the database, to be retrieved with mere keystrokes.
The beauty (and terror) of DevonThink is that opening a new database is like staring into a slate grey abyss: DevonThink allows you to fashion pretty much any folder structure you like, to impose any order you wish upon your data universe (Figure 1). There are thus as many database configurations as there are people in the world: each one a unique reflection of the brain which produced it. What I found most helpful when getting started was to look at as many examples of how others had used DevonThink that I could find. I therefore offer the following as just one example of how DevonThink can be used for history research.
Given limited space, I can only touch on three of the many useful features of DevonThink: flexible filing, smart groups, and textual concordance. An expanded version of this essay is available on my blog (the URL for which is appended below).
DevonThink’s flexible filing structure is one of its biggest attractions for me: it allows you to create any root file structure you wish, beginning with the most basic unit, a “group”.
Figure 1
The bulk of material in my PhD database is contained in two groups: primary material (“Archives”) and secondary material (“Library”). In my “Archives” group, my substructures usually mimic those of the archives I visited. I allocate one group for each physical repository I consulted (e.g. “British Library”, “The National Archives, UK”), and within that, one group per source I consulted from that repository. With archives, I usually replicate the filing structure of the archive itself, as this helps with citation later on. In my “Library” group, I have a group per book or article, listed by author/date of publication. Each seminar, interview, book, journal and archive file thus has a group of its own; everything I know about or learn from that source, and frequently the source itself in PDF, JPG or DOC form, is in there.
DevonThink also has, alongside its normal groups, the ability to create “Smart Groups”, which automatically collate data from anywhere in the database matching a given set of boolean conditions. One way in which I use smart groups is to auto-sequence my archival data chronologically. As a modern historian, almost all my primary data is time-specific down to the day or month, so I got into the habit of naming my files according to a strict YYYY.MM.DD format. This enabled me to create a collection of smart groups—one for each year, each of which automatically contains all source documents and notes pertaining to that year. This is a simple enough matter of conditionals (e.g. ‘For the smart group called “1945”, include all files whose title includes the string “1945”‘). So for example, in Figure 2, the file highlighted green is a letter to the British colonial office dated 14 May 1948. This file was automatically included in my 1948 smart group because it matches the specified conditional. And because all files are named according to the same format, with the date first, I can sort them alphabetically and get a list of documents in ascending chronological order over the course of a single year.
Perhaps the most unique feature of DevonThink is textual concordance. Every word in the database is indexed and weighted according to frequency of appearance. DevonThink can thus, over time, “intuit” relationships between documents in your database: based on the frequency of rare words within a single file, it attempts to tell you what other documents in your database are likely to be relevant. I find this to be particularly useful for historical work, since we collect data sequentially over time, but must, in writing up, make connections between more recent acquisitions and data which may have been acquired more than a year ago. In this way, DevonThink can actually help you think: it intelligently keeps material in circulation, in sight and therefore, in mind. The key to this, of course, is that all your data must be searchable text. The Pro Office version of DevonThink therefore has fantastic OCR-recognition: it can literally “read” PDFs—even photographs of typescript, which is particularly useful for historians—and parse them as text.
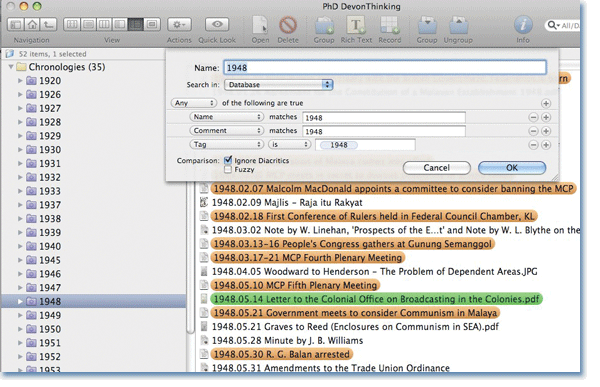
Figure 2
OCR functionality is limited to Pro Office, the most expensive version of DevonThink. Having used both Pro and Pro Office, I would say that the OCR recognition alone is worth the purchase, though this endorsement comes with the following weighty caveat: As someone who works also with Chinese, Indonesian and Malay material, I’ve found DevonThink to be inadequate for dealing with non-English and non-Romanized material. Having more than one language in the database stymies concordance; non-Romanized words are totally unsearchable. Artificial intelligence, unsurprisingly, has its limits.
Digital advances aside, therefore, I will say this. Even having spent five years working with DevonThink, I’ve arrived at the conclusion that, despite the allure of a fully paperless existence, there is—at least for me—still no escaping the “meatworld.” The teleology of progress implicit in the three different versions of DevonThink, at the pinnacle of which is the fully-OCR-capable, scanner-integrated DevonThink Pro Office, reveals the conviction of the paperless dream embedded in Devon Technologies’ vision. Perhaps it will all come to that in a matter of time. And yet I still think that there are routes of thought which are impossible, or waylaid, by depending fully on the database. There is a certain physicality to writing by hand rather than typing, to rereading rather than searching, which sinks data into one’s body and makes it available for connection, synthesis and analysis in a way which even an intelligent database can still only at best mimic. All this is quite apart from the fact that historians are still welded to non-digitized archives and materials, and quite apart from the monolingual imperatives of DevonThink. I love my database as an unparalleled system for containing, managing and organizing data; for that alone, it has changed my research life, and may well change yours. I’m just less sure that it’s as good to think with as we may hope, and I’m particularly unconvinced that historians will be able to fully achieve the paperless dream anytime soon.
Rachel Leow completed her PhD in History at Cambridge University in 2011 and is presently Prize Fellow in Economics, History and Politics at Harvard University. She blogs periodically at A Historian's Craft and ran a workshop on technology and historical research methods at Harvard in 2012, the notes for which are available online.


