 If you’ve ever filled out a form on the web, you’ve probably had to retype those distorted letters to prove that you are in fact a human being and not a program written to send spam. This process, known as “CAPTCHA” (an acronym for “Completely Automated Public Turing test to tell Computers and Humans Apart”), was first introduced by Yahoo.com in 2000 and is now used 60 million times per day. From the perspective of someone filling out the form, it is at best a necessary evil. Now, however, a team at Carnegie Mellon has developed a program dubbed reCAPTCHA that uses the CAPTCHA process and the millions of people filling out web forms to help digitize books that will ultimately be made available for free by the Internet Archive.
If you’ve ever filled out a form on the web, you’ve probably had to retype those distorted letters to prove that you are in fact a human being and not a program written to send spam. This process, known as “CAPTCHA” (an acronym for “Completely Automated Public Turing test to tell Computers and Humans Apart”), was first introduced by Yahoo.com in 2000 and is now used 60 million times per day. From the perspective of someone filling out the form, it is at best a necessary evil. Now, however, a team at Carnegie Mellon has developed a program dubbed reCAPTCHA that uses the CAPTCHA process and the millions of people filling out web forms to help digitize books that will ultimately be made available for free by the Internet Archive.
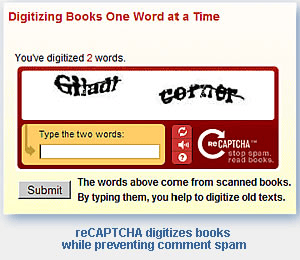
The process is explained fully on the reCAPTCHA web site, but read on for the gist of it. reCAPTCHA gathers scanned images from books the Internet Archive project is attempting to digitize and supplies them to participating web sites. When users of those sites fill out forms, they will be asked to retype two words that appear in the image. When the user correctly enters these words, he or she will have contributed to the accurate digitization of books while submitting the form they originally intended.
The AHA is in the process of adding the reCAPTCHA program to all of its web forms (see it in action on The Next Generation of History Teachers comment page), and the technical staff of the association enthusiastically endorses its use elsewhere.
This post first appeared on AHA Today.



