The new methods of “big data” analysis can inform and expand historical analysis in ways that allow historians to redefine expectations regarding the nature of evidence, the stages of analysis, and the claims of interpretation.1 For historians accustomed to interpreting the multiple causes of events within a narrative context, exploring the complicated meaning of polyvalent texts, and assessing the extent to which selected evidence is representative of broader trends, the shift toward data mining (specifically text mining) requires a willingness to think in terms of correlations between actions, accept the “messiness” of large amounts of data, and recognize the value of identifying broad patterns in the flow of information.2
Our project, An Epidemiology of Information, examines the transmission of disease-related information about the “Spanish flu,” using digitized newspaper collections available to the public from the Chronicling America collection hosted by the Library of Congress. We rely primarily on two text mining methods: (1) segmentation via topic modeling and (2) tone classification. Although most historical accounts of the Spanish flu make extensive use of newspapers, our project is the first to ask how looking at these texts as a large data source can contribute to historical understanding of this event while also providing humanities scholars, information scientists, and epidemiologists with new tools and insights. Our findings indicate that topic modeling is most useful for identifying broad patterns in the reporting on disease, while tone classification can identify the meanings available from these reports.
Topic Modeling with Segmentation
The corpus we used to develop text mining methods comprises twenty weekly papers from across the United States for the years 1918–1919. Topic modeling algorithms identify a topic by discovering words that appear together frequently. To define the topics in our corpus, we extracted “text chunks” made up of three sentences before and after identified disease terms (influenza, flu, epidemic, and grippe). The algorithm identifies which words appear frequently with these terms, how those terms might be grouped, and how groupings of words change over time. The output of the algorithm is visualized as a timeline that is segmented to show the time boundaries of discovered segments. Topics discovered within each segment using topic modeling are represented by their top 20 terms and visualized as tag clouds.
Topc modeling with segmentation identified three distinct breaks in reporting from late August 1918 to early January 1919 (fig.1). During the first period, August 21 to October 6, the appearance of terms such as spread, Spanish, public, army, death, service, and epidemic (1.a.) suggest reporting from locations beyond the local community. By contrast, terms such as son, home, boy, and visit in the bottom right cloud (1.b.) suggest reports about community members who fell victim to influenza, either locally or farther away.
-600x450.jpg)
In the second segment, terms such as fever, sick, patient, cold, germ, disease, and spread in the top left cloud (2.a.) reflected increased reports on medical dimensions, because these terms convey the sort of detail associated with firsthand experience with the disease. The middle cloud (2.b.) illustrates reporting on public health measures, including school closings, statements by health boards, and numbers of cases and deaths. The bottom left cloud (2.c.) provides the most obvious evidence of local connections, as family terms appear in connection with locations (home), time (morning, day, and week), and behaviors (visit, call, and return).
In the third segment, the top right cloud (3.a.) reflects continued coverage of the disease on a personal level, and the bottom right cloud (3.b.) indicates coverage of statements from health authorities about influenza. In the fourth segment, in addition to the bottom right cloud (4.a.), which indicates the continued significance of personal connections, terms like attend and return in the bottom left cloud (4.b.) suggest coverage of the reopening of schools and other public gatherings. The middle cloud (4.a.) indicates that influenza is increasingly associated with words common in health-related advertisements (tonic, build, strength, medicine).
A close reading of selected articles by our project team confirms the patterns of coverage identified by the algorithms. The initial reports of disease outbreaks in military camps or cities on the Atlantic coast are followed by more frequent, complex, and varied reporting of the impact of disease and the implementation of public health measures at the local level, with final reports on the decline of disease, along with a continued presence in public health recommendations and commercial advertising. Because topic modeling with segmentation renders a chronological index of broad trends, visualizing word relationships that suggest patterns of coverage and changes over time, it is most effective as a method of identifying trends that should then be explored further with close reading.
Tone Classification
Historians have long been interested in how the tone of newspaper reporting shapes popular attitudes toward epidemic disease. Our project contributes to this scholarship by classifying the tone of newspaper reporting on a scale larger than would be possible by human readers using conventional methods. The project team developed four classifications for influenza reporting:
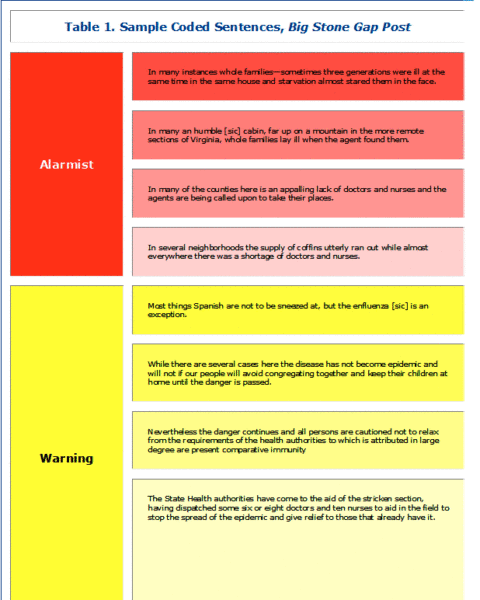
- Alarmist: emphasizing the danger posed by the epidemic and the number of victims;
- Warning: urging measures to prevent infection and contain the spread of disease;
- Reassuring: encouraging a sense of optimism by minimizing the danger; and
- Explanatory: providing information in a neutral manner.
Analyzing these tones in news reporting allows both historians and epidemiologists to explore a common research question: How does the tone of reporting correspond to the threat of disease as it spreads, reaches peak levels, prompts public health interventions, and then declines to normal levels?
To develop the tone classification, we trained a machine learning classifier to detect the four tones using approximately 300 sentences from newspapers (all of these sentences were corrected manually to eliminate the many errors introduced by optical character recognition). First, four coders, from humanities and social science fields, attained a moderate level of agreement in their classifications. We then trained the classifier on one set of data and evaluated its performance on another, “held out” data. Repeating this process four times, the classifier gave the “right” answer on average 72 percent of the time, which is a satisfactory performance for this approach.
The classifier thus trained and evaluated was applied to 65 transcribed articles (445 extracted sentences) published between October 2 and December 18 in the Big Stone Gap Post, a Virginia newspaper. The classifier identified a high proportion of reassuring reports at the start of the epidemic. The November 6 issue was a low point in reassuring reports, and there was an uptick toward the end of the epidemic. The highest proportion of warning sentences appeared in the October 30 and November 13 issues, the peak of the epidemic in this community and across Virginia.
Algorithmic tone classification can clearly produce interpreted results that show changes in reporting over time and across a broad selection of texts. It is therefore potentially valuable as a knowledge discovery technique, but only if it can be refined to identify the complex sentences characteristic of early-20th-century newspapers. The challenge of classifying tones automatically can be illustrated by the ways that the Big Stone Gap Post associated alarming statements about “the crisis that is surely coming” or “the plague of influenza that is now sweeping over the state” with more reassuring promises that the influenza “is seldom a menace to life” and “The people of Big Stone Gap are to be congratulated that as yet influenza has not ravaged the town to the extent which has been feared.” As these examples suggest, newspapers often combined alarmist and reassuring tones in the same sentences, which complicates the classification process. In reading the actual classified sentences, it is also clear that the classifier misidentified some, particularly those conveying alarm. Tone classification illustrates the real challenges that the complexity of written language poses for data mining.

Conclusion
Data mining offers historians a set of novel methods for identifying patterns, recognizing shifts, and gauging tone in a corpus of primary sources. In our case study, these methods suggest ways to track the spread of information on a national level through automated methods of text mining. Historians need to recognize that new methods must be combined with more traditional ones to check accuracy and interpret the meaning of words in context. The recognition that sentences in newspaper articles are simultaneously a representation of social experience, a set of discursive structures, and an instrument for communication eventually leads the historian back to the careful reading of original documents.
But across larger aggregates of data, topic modeling with segmentation can reliably demonstrate how local weekly newspapers mixed personal reporting of illness with national accounts of the disease sweeping the country, and how the reporting changed over time as the disease was anticipated by, came into, and then left particular communities. Similarly, the tone analysis exercise draws attention to the multifaceted sentiments implicit in a text and enables historians to pose questions about the interplay between reporting styles and the spread of the disease. These text mining methods have potential to reshape historical analysis, but only with further efforts to increase accuracy, recognize complexity, and acknowledge variety in the nature of the reporting.
Notes
Funding for this project came from the Digging into Data Challenge, administered by the National Endowment for the Humanities Office of Digital Humanities, and from the Department of English, the Institute for Society, Culture, and Environment, the Department of History, and the Department of Computer Science at Virginia Tech.
- The most recent debate over using “big data” methods to contribute to humanities scholarship was initiated by the publication of Jean-Baptiste Michel et al., “Quantitative Analysis of Culture Using Millions of Digitized Books,” Science 331, no. 6014 (January 14, 2011): 176. See also the Culturomics team’s engagement with criticisms in “Big Picture,” Culturomics: Resources. For responses by historians and humanities scholars, see John Bohannon, “Google Books, Wikipedia, and the Future of Culturomics,” Science 331, no. 6014 (January 14, 2011): 135; Anthony Grafton, “Loneliness and Freedom,” Perspectives on History (March 2011),; James Grossman, “‘Big Data’: An Opportunity for Historians,” Perspectives on History (March 2012). [↩]
- For this argument about changing scholarly approaches, especially in the social sciences, see Viktor Mayer-Schoenberger and Kenneth Cukier, Big Data: A Revolution That Will Transform How We Live, Work, and Think (New York: Houghton Mifflin Harcourt, 2013). [↩]
E. Thomas Ewing is a professor of history and associate dean for research in the College of Liberal Arts and Human Sciences. Samah Gad is a PhD candidate in the Department of Computer Science. Bernice L. Hausman is the Edward S. Diggs Professor in the Humanities and professor of English, as well as professor at the Virginia Tech Carilion School of Medicine. Kathleen Kerr is a PhD candidate in the Rhetoric and Writing Program in the Department of English. Bruce Pencek is the college librarian for social sciences and history. Naren Ramakrishnan is the Thomas L. Phillips Professor of Engineering in the Department of Computer Science, all at Virginia Tech.


